GIL
CPython 在解释器进程级别有一把锁,叫做GIL,即全局解释器锁。 GIL 保证CPython进程中,只有一个线程执行字节码。甚至是在多核CPU的情况下,也只允许同时只能 有一个CPU核心上运行该进程的一个线程。
- CPython中
- IO密集型,某个线程阻塞,GIL会释放,就会调度其他就绪线程(线程因为IO阻塞,这个线程的GIL锁就会解开)
- CPU密集型,当前线程可能会连续的获得GIL,导致其它线程几乎无法使用CPU(加锁解锁是需要时间的)
- 在CPython中由于有GIL存在,IO密集型,使用多线程较为合算;CPU密集型,使用多进程,要绕开GIL
Python中绝大多数内置数据结构的读、写操作都是原子操作。
由于GIL的存在,Python的内置数据类型在多线程编程的时候就变成了安全的了,但是实际上它 们本身 不是线程安全类型。
cpython中因为GIL的存在,多线程中对CPU利用效率是低下的。IO密集型的影响并不大,CPU密集型对效率影响较大。CPU密集型可采用多进程,每个进程有一个主线程进行计算,绕开这个把锁。
但是多进程间通信的代价很高,所以要减少多进程间的通信。
多进程
python中使用multiprocessing模块实现多进程,有几个类:
Process类
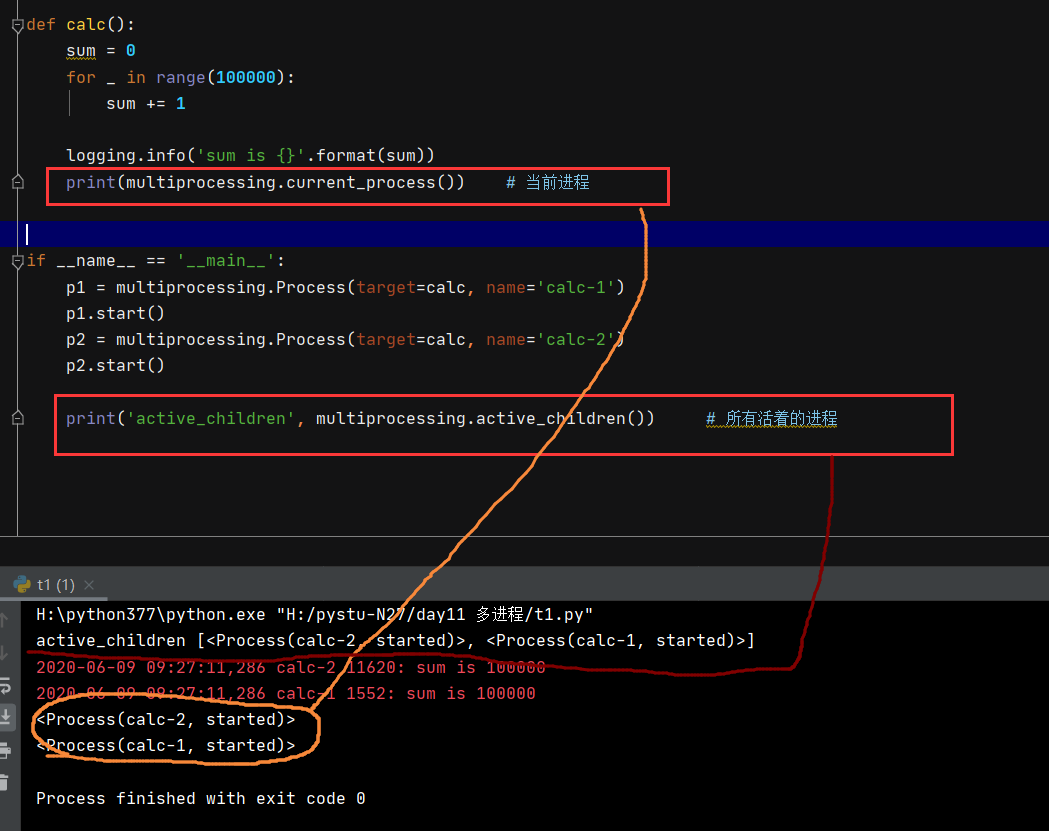
进程的使用方式类似线程,都要创建一个进程实例,然后启动它。
但是这个实例必须在 main中
多进程计算:
# encoding = utf-8
__author__ = "mcabana.com"
import multiprocessing
import logging
import datetime
FORMAT = "%(asctime)s %(processName)s %(process)d: %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)
def calc():
sum = 0
for _ in range(1000000000):
sum += 1
logging.info('sum is {}'.format(sum))
# print(multiprocessing.current_process()) # 当前进程
if __name__ == '__main__': # 进程必须在main中
start = datetime.datetime.now()
ps = []
for i in range(4):
p = multiprocessing.Process(target=calc, name='calc-{}'.format(i)) # 创建一个进程
p.start() # 启动进程
ps.append(p)
print('active_children', multiprocessing.active_children()) # 所有活着的进程
for p in ps:
p.join() # join
deltime = (datetime.datetime.now() - start).total_seconds()
print(deltime)
进程属性:
| 名称 | 说明 |
| pid | 进程id |
| exitcode | 进程的退出状态码 |
| terminate() | 终止指定的进程 |
进程中执行的函数的返回值目前拿不到。
因为GIL线程是交替执行的,而进程则是真正的并行。
进程间同步
Python在进程间同步提供了和线程同步类似的类,使用的方法一样,使用的效果也类似。
不过,进程间代价要高于线程间,而且系统底层实现是不同的,只不过Python屏蔽了这些不同之处,让用户简单使用多进程。
multiprocessing模块还提供共享内存、服务器进程来共享数据,还提供了用于进程间通讯的Queue队列、Pipe管道。
通信方式不同:
网络通信是进程间通信的主要方式。
- 多进程就是启动多个解释器进程,进程间通信必须序列化、反序列化
- 数据的线程安全性问题,如果每个进程中没有实现多线程,GIL可以说没什么用了
多进程多线程的选择
- 对于IO密集型
- 可使用多线程, 因为需要等待IO的原因, 可以切换到其他线程执行, 真并行并不会调高多少性能, 所以 GIL的影响并不大。
- 而且线程的开销是小于进程的, 所以使用多线程性能更优
- 对于CPU密集型
- 可使用多进程
- 多线程中因为GIL的存在, 相当于单线程执行, 多核优势无法发挥, 并且多线程还会竞争cpu锁, 所以性能不高
- 使用多进程只创建一个主线程,这样就不会参数线程锁竞争, 从而利用多核心并发的优势, 提高执行效率。
池
对于一些创建代价很高,频繁使用的,往往使用 池 来处理,这样可以重复利用,减少开销。
concurrent.futures
3.2 版本引入的模块,处理高并发问题。
提供了2个池执行器:
ThreadPoolExecutor 异步调用的线程池的Executor
ProcessPoolExecutor 异步调用的进程池的Executor
执行器可以分派任务,执行任务,结束任务。
线程池:
| 方法 | 含义 |
| ThreadPoolExecutor(max_workers=1) | 池中至多创建max_workers个线程的池来同时异步执行,返回 Executor实例 支持上下文,进入时返回自己,退出时调用shutdown(wait=True) |
| submit(fn, *args, **kwargs) | 提交执行的函数及其参数,如有空闲开启daemon线程,返回Future 类的实例。 fn就是目标函数 |
| shutdown(wait=True) | 清理池,wait表示是否等待到任务线程完成 |
future类的方法,线程池中启动一个线程或进程,将其赋给future
| 方法 | 含义 |
| done() | 判断是否执行成功或执行完成。 如果调用被成功的取消或者执行完成,返回True |
| cancelled() | 如果调用被成功的取消,返回True |
| running() | 如果正在运行且不能被取消,返回True |
| cancel() | 尝试取消调用。如果已经执行且不能取消返回False,否则返回True,取消,结果也是done的,running态不可取消 |
| result(timeout=None) | 取返回的结果,timeout为None,一直阻塞等待结果返回;timeout设置到期,抛出 concurrent.futures.TimeoutError 异常 一般结合done() 使用 |
| exception(timeout=None) | 取返回的异常,timeout为None,一直等待返回;timeout设置到期,抛出 concurrent.futures.TimeoutError 异常 |
线程池的使用示例:
# encoding = utf-8
__author__ = "mcabana.com"
import threading
import datetime
import time
import logging
from concurrent.futures import ThreadPoolExecutor
start = datetime.datetime.now()
FORMAT = "%(asctime)s %(threadName)s %(thread)d: %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)
# 先定义一个线程池执行器
executor = ThreadPoolExecutor(4) # 此线程池中最多创建 4 个线程异步执行
# 如果是None 则是 os.cpu_count() * 5 或者 1 * 5
def calc():
sums = 0
logging.info('in the worker')
for _ in range(1000000000):
sums += 1
return threading.current_thread(), sums # 执行函数的返回值就是 future.result()
f = executor.submit(calc) # 如果线程池没有达到最大数,则启动线程,如果满了就等待
# 用线程池启动, 返回一个future给f, f中包含了启动的线程的信息
# 线程池创建线程,其实就是调用的threading.Thread(), daemon=True
print(type(f), f) # running状态
while True: # 因为没有阻塞主线程,所以要手动判断线程是否执行完了,多个线程要逐个判断
time.sleep(1)
if f.done(): # 因为没有阻塞主线程,所以要手动判断f是否执行完了
print(f.result()) # 如果执行完,打印结果。如果没有执行完就打印,会阻塞在这
break
# 此时f状态为finished
# 关闭线程池执行器
executor.shutdown() # 关闭 会等待所有线程执行完
deltime = (datetime.datetime.now() - start).total_seconds()
print('end ~~~~~~~~~~~~~~~~~~~~~~', deltime)
如果要启动多个线程:
# encoding = utf-8
__author__ = "mcabana.com"
import threading
import datetime
import time
import logging
from concurrent.futures import ThreadPoolExecutor
start = datetime.datetime.now()
FORMAT = "%(asctime)s %(threadName)s %(thread)d: %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)
# 先定义一个线程池执行器
executor = ThreadPoolExecutor(4) # 此线程池中最多创建 4 个线程异步执行
# 如果是None 则是 os.cpu_count() * 5 或者 1 * 5
def calc():
sums = 0
logging.info('in the worker')
for _ in range(100000000):
sums += 1
return threading.current_thread(), sums # 执行函数的返回值就是 future.result()
fs = []
# 多个启动线程
for i in range(4):
f = executor.submit(calc)
fs.append(f) # 加入线程列表
# 获取多个线程的状态
while True:
time.sleep(1)
flag = True
for f in fs:
if f.done(): # 判断每个线程是否done了
logging.info(f.result())
flag = f.done() and True # 有一个线程没有done(),就会是False
if flag: # 如果是False,就继续等待
break
# 关闭线程池执行器
# executor.shutdown() # 关闭 会等待所有线程执行完
deltime = (datetime.datetime.now() - start).total_seconds()
print('end ~~~~~~~~~~~~~~~~~~~~~~', deltime)
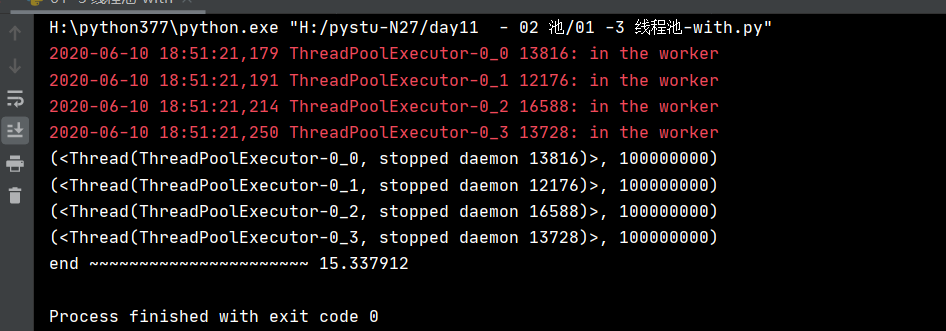
因为 执行器是支持上下文的,所以可以使用with管理,如下:
# encoding = utf-8
__author__ = "mcabana.com"
import threading
import datetime
import logging
from concurrent.futures import ThreadPoolExecutor
start = datetime.datetime.now()
FORMAT = "%(asctime)s %(threadName)s %(thread)d: %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)
# 先定义一个线程池执行器
executor = ThreadPoolExecutor(4) # 此线程池中最多创建 4 个线程异步执行
# 如果是None 则是 os.cpu_count() * 5 或者 1 * 5
def calc():
sums = 0
logging.info('in the worker')
for _ in range(100000000):
sums += 1
return threading.current_thread(), sums # 执行函数的返回值就是 future.result()
with executor: # 离开时要调用ThreadPoolExecutor.__exit__()方法,而源码中是self.shutdown(wait=True)
# 要等待 各个线程执行完成。就是主线程会阻塞在这。
fs = []
# 多个启动线程
for i in range(4):
f = executor.submit(calc)
fs.append(f) # 加入线程列表
for f in fs: # 主线程执行到这时,所有线程肯定都执行完成了是done的,所以可以直接获取result()
print(f.result())
# # 获取多个线程的状态
# while True:
# time.sleep(1)
# flag = True
# for f in fs:
# if f.done(): # 判断每个线程是否done了
# logging.info(f.result())
#
# flag = f.done() and True # 有一个线程没有done(),就会是False
# if flag: # 如果是False,就继续等待
# break
#
# 关闭线程池执行器
# executor.shutdown() # 关闭 会等待所有线程执行完
deltime = (datetime.datetime.now() - start).total_seconds()
print('end ~~~~~~~~~~~~~~~~~~~~~~', deltime)
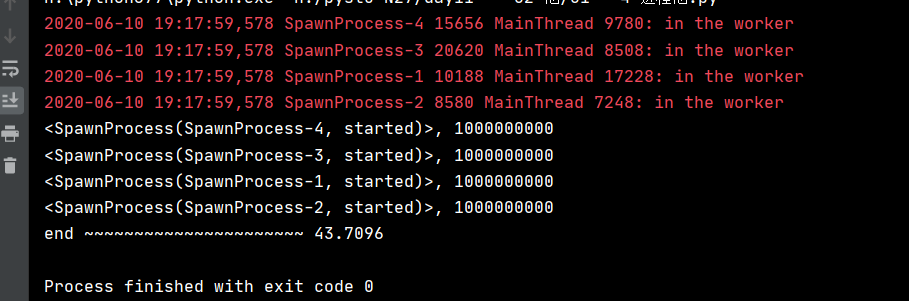
进程池:
进程池的使用方法与线程池完全相同,只需要更改下 使用的类名称即可。
其他不变,如下:
# encoding = utf-8
__author__ = "mcabana.com"
import multiprocessing
import datetime
import logging
from concurrent.futures import ProcessPoolExecutor
start = datetime.datetime.now()
FORMAT = "%(asctime)s %(processName)s %(process)d %(threadName)s %(thread)d: %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)
def calc():
sums = 0
logging.info('in the worker')
for _ in range(1000000000):
sums += 1
return "{}, {}".format(multiprocessing.current_process(), sums) # 执行函数的返回值就是 future.result()
if __name__ == '__main__': # 进程要写在 main 中
# 先定义一个进程池执行器
executor = ProcessPoolExecutor(4) # 此进程池中最多创建 4 个进程同步执行
# 如果是None 则是 os.cpu_count() * 5 或者 1 * 5
with executor:
fs = []
# 多个启动进程
for i in range(4):
f = executor.submit(calc)
fs.append(f) # 加入进程列表
# 获取多个进程的执行结果
for f in fs:
print(f.result())
# 关闭进程池执行器
executor.shutdown() # 关闭 会等待所有进程程执行完
delta = (datetime.datetime.now() - start).total_seconds()
print('end ~~~~~~~~~~~~~~~~~~~~~~', delta)
https://www.hugbg.com/archives/2824.html


评论