概念介绍
正排索引
在说倒排索引之前,先说下正排索引。正排索引又叫“前向索引”,它为每一个文档建立一个ID,通过ID可以定位到文档位置,就像书籍的“目录”一样,每一个章节都会有一个“页码”,通过这个目录可以很方便的找到章节在书中对应的位置。如果要新增一个章节只需要在目录中添加 章节与页码的对应关系;如果删除一个章节可以通过目录找到对应的页码,删除这页码并在目录中删掉这个映射即可。正排索引就是文档ID到文档内容的关系。

如果要搜索某个关键词在哪些文档中出现,则需要全文扫描所有文档,才能得出结果。
正排索引结构简单,使用方便,但在关键词搜索时效率低,只能在简单场景下使用。
倒排索引
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。倒排索引可以看做每个词的列表的集合。
建立倒排索引会把文档拆分成一个的“单词”(称之为 词条 或者 token),并创建一个包含所有不重复词条的排序列表,然后列出每个词条出现次数,出现在哪个文档及那个位置。如:
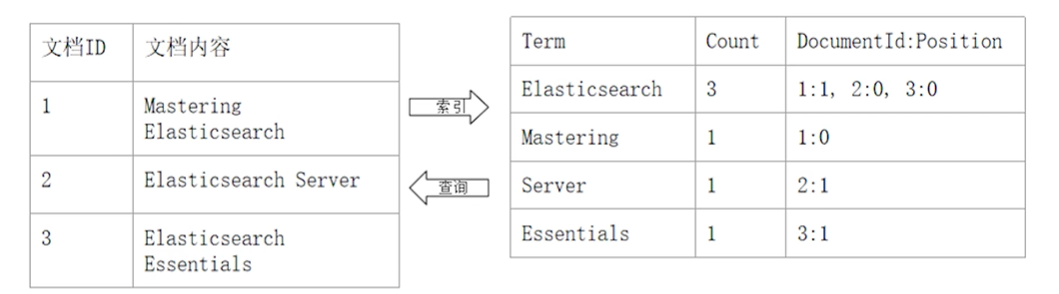
如图所示,ElasticSearch 共出现3次,分别是 1号文档的第1个单词(单词计算从0开始),2号文档的第0个单词,3号文档的第0个单词 1:1,2:0,3:0
通过这种索引,我们可以快速的找到某个单词出现的频率,以及在文档中的位置。
倒排索引的核心组成:
倒排索引包含两个部分
- 单词词的(Term Dictionary),记录所有文档的单词。记录单词到倒排列表的关联关系
- 单词词典一般比较大,可以通过B+树 或 哈希拉链法实现,以满足高性能的插入和查询
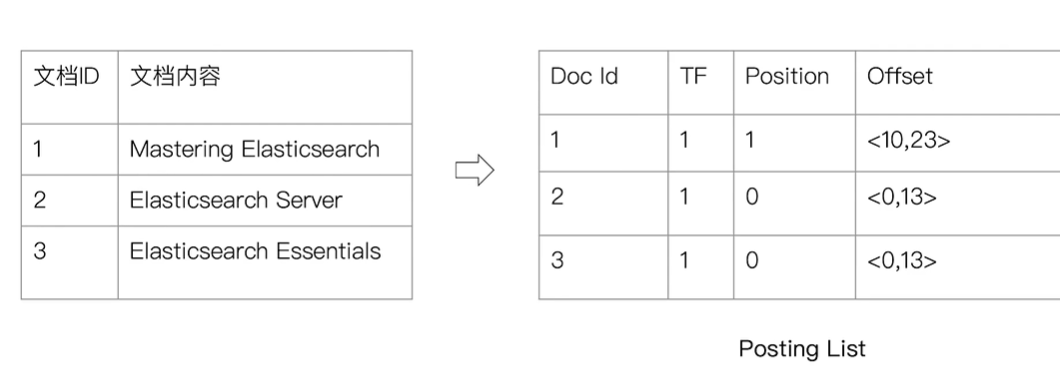
- 倒排列表(Posting List) 记录了单词对应的文档结合,由倒排索引项组成
- 倒排索引项(Posting)
- 文档 ID
- 词频 TF - 该单词在文档中出现的次数,用于相关性评分
- 位置(Position) - 单词在文档中分词的位置,用于语句搜索
- 偏移 (offset) - 记录单词在文档中的结束位置,实现高亮显示
- 倒排索引项(Posting)
ElasticSearch 中每个json文档中的每个字段都有自己的倒排索引。
- 可以指定某些字段,不做索引;
- 优点:节省磁盘空间
- 缺点:这些字段不能被搜索
分词处理
前面说到“倒排索引”是记录的每个不重复单词的信息,那么ElasticSearch 如何将一个文档,分成一个个的单词,分词过程中 大小写单词如果处理,同义词与近义词算不算一个词。
Analysis 整个过程是通过分词器(Analyze)实现的,ElasticSearch中内置了多种分词器,也可按需定制分词器。
ElasticSearch 中的分词器,不光在数据写入时转换词条,匹配查询语句时也需要用相同的分析器对查询语句进行分析。
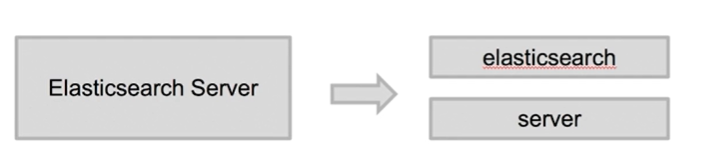
Analyzer 的组成
分词器是专门处理分词的组件,由三部分组成,其组成及处理过程如下:
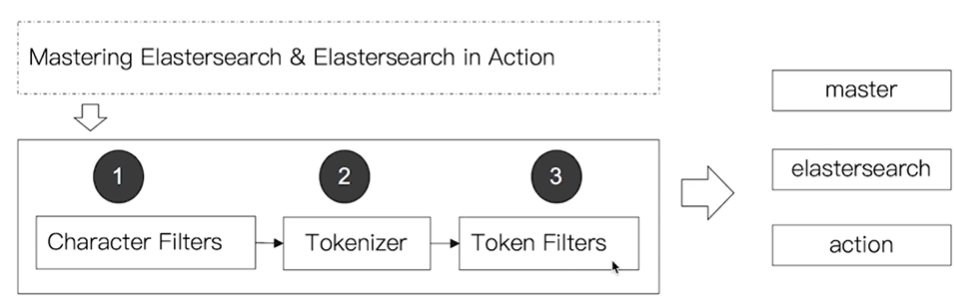
- Character Filters:获取原始文本进行处理,例如去除html标签等
- Tokenizer:按照规则将文本切分为单词
- Token Filters: 将切分的单词进行加工,大小写处理,删除 stopwords,增加同义词等
ElasticSearch 内置分词器
| Simple Analyzer | 按照非字母切分(符号被过滤),小写处理 |
| Stop Analyzer | 小写处理,停用词过滤(the,a,is) |
| Whitespace Analyzer | 按照空格切分,不转小写 |
| Keyword Analyzer | 不分词,直接将输入当作输出 |
| Patter Analyzer | 正则表达式,默认 \W+ (非字符分隔) |
| Language | 提供了30多种常见语言的分词器 |
Analyzer API的使用
可通过三种方式查看 分词器是如何工作的;
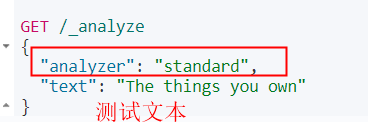
1、直接指定Analyze 进行测试,使用standard 分词器

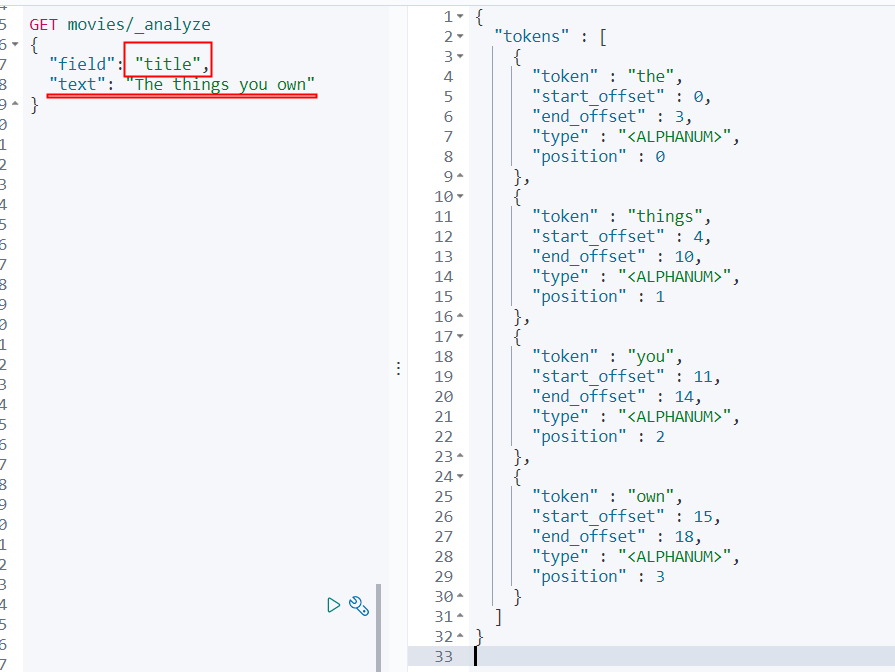
2、指定索引的字段进行测试
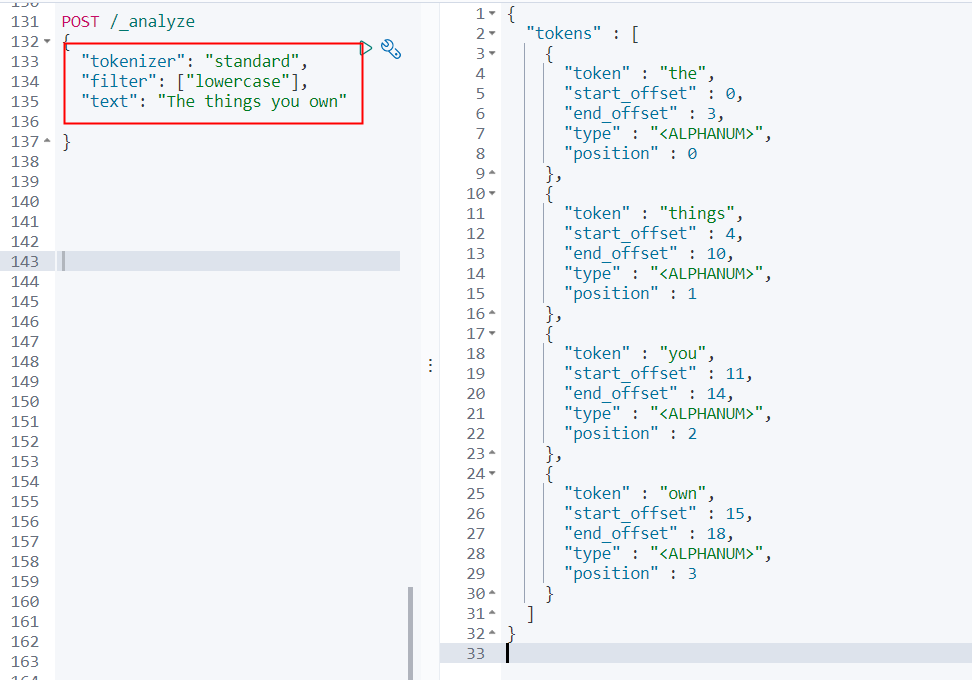
3、自定义分词进行测试
ES内置分词器介绍
Standard Analyze 介绍

Simple Analyze

非字母切分,一些下划线什么的都会当做一个分割符,大写会改为小写处理,数字被删除了

Whitespace Analyze

Stop Analyze

Keyword Analyze

Pattern Analyze
默认使用\w+ 以非字母为分隔符,同时会将大写转小写

Language Analyze
用于适配多种语言,可以指定语言。
中文分词
中文分词难点:
- 一个中文句子要切割成一个个的“词”,而不是“字”;
- 中文中没有明显的分隔符(英文中有空格);
- 中文分词需要结合上下文分析
- 这个苹果,不大好吃/ 这个,苹果,不大,好吃
ICU Analyzer
icu Analyze 需要手动在es集群个节点分别安装,国内安装较慢,耐心等待
elasticsearch-plugin install analysis-icu


现在对中文分词,做的并不是特别好。此外还有一些开源的中文分词器:
- IK
- 支持自定义词库,支持热更新分词字典
- https://github.com/medcl/elasticsearch-analysis-ik
- THULAC
https://www.hugbg.com/archives/1923.html?viewall=true



2020-04-19 12:35 下午 1F
程序漏洞叫特性,设计漏洞叫特色 —沃·兹基·硕得