基本概念一: 文档,索引,REST API
文档:
ElasticSearch 是面向文档的,文档是所有可搜索数据的最小单位。如cerebro中

比如: messages 日志中的一条日志,一张专辑里面的一首歌曲,这些在es中都是一个文档。
文档特性:
ElasticSearch 会把“文档”序列化成一个json格式数据,保存到es中。
- json 对象由“字段”组成;
- 每个字段又都有其数据类型(字符串/整形/布尔型/等);
- 每一个文档,都有一个UID, 这个uid可以手动指定,也可以自动生成;
- 需要注意字段是可以嵌套的;
例如:
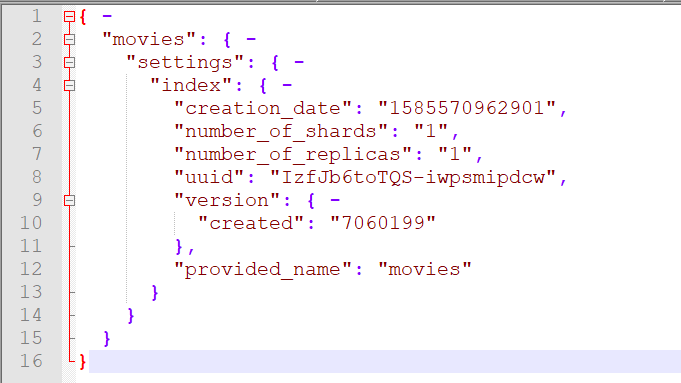
文档元数据:
ES中的文档会有一个“元数据”,通过元数据来表示文档的一些属性信息。例如:

索引
索引可以看做是一类“文档”的集合,上面提到message日志中的一条日志是一个文档,那么整个message文件可以看做一个索引。同样的一张专辑是一个索引,里面的每一首歌曲则是一个个的文档。
- 每个索引都有自己的Mapping定义,用来定义包含的文档的字段名,和字段类型;
- 索引中的数据分散在shard上;
- 索引通过Mapping定义文档中的字段的类型结构;
- 索引通过setting 定义文档中的数据分布,就是关于shard的设置;
REST API
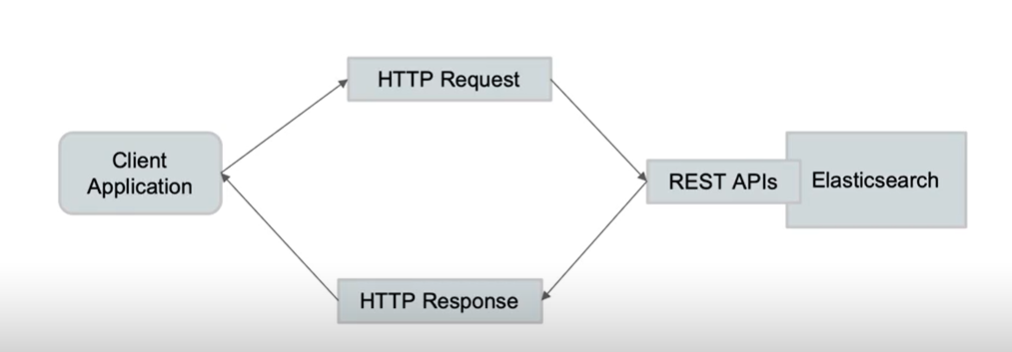
ElasticSearch 的rest api 用于其他语言与es交互使用
基本概念二:节点,集群,分片及副本
集群
ElasticSearch 作为一个分布式集群,具有其可用性和扩展性:
- 高可用性
- 服务可用性 - 允许有节点停止服务,不会影响整个集群的服务
- 数据可用性 - 部分节点数据丢失,集群不会丢失数据
- 可扩展性
- 请求量提升/数据的不断增长(将数据分布到所有节点)
- 实现存储的水平扩容
分布式架构:
- 不同的集群通过不同的名字来区分,名字可以自定义;
- 一个集群可以有一个或多个节点
节点
- 节点其实就是一个ElasticSearch 的实例
- 本质上是一个java 进程;
- 一台机器上可以运行多个ElasticSearch 进程,生产建议一台机器运行一个实例;
- 每一个节点可以设置名字,node.name 指定
- 每一个节点启动后,会分配一个UID,保存在data目录下,唯一。
节点类型:
关于Master-eligible nodes 和 Master Node
- 每一个节点启动,默认就是一个Master eligible 节点
- 可以设置 node.master: false 禁止
- Master-eligible 节点可以参加选举,称为Master 节点;
- 当第一个节点启动时候,会把自己选举为Master节点;
- 每个节点都保存了集群状态,只有Master节点可以修改集群信息;
- 集群状态 - Cluster State 维护一个集群中必要的信息,包括:
- 所有的节点信息;
- 所有的索引,及其Mapping 和 Setting信息
- 分片的路由信息
- 集群状态 - Cluster State 维护一个集群中必要的信息,包括:
- 如果任意节点都能修改信息,会导致数据的不一致
关于Data Node 与 Coordinating Node
- Data Node
- 数据存储节点,保存分片数据;
- 通过增加Data Node ,实现存储扩容;
- Coordinating Node
- 负责接收Client的请求,并将请求分发到合适的节点,最终把结果汇集到一起;
- 每个节点默认都起到了Coordinating Node的职责;
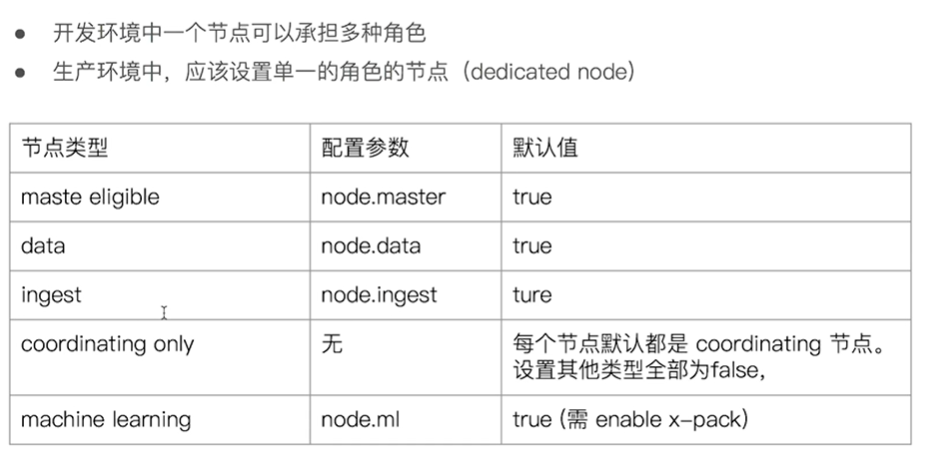
其他类型的节点:

每个节点在启动时,通过读取配置文件,来确认自己承担什么样的角色,配置参数如下:
分片 shard
分片分为两类:主分片 和 副本分片
- 主分片- Primary Shard
- 用以解决数据的水平扩展问题。通过主分片,可以将数据分布到集群内的所有节点上
- 一个分片是一个运行的Lucene 的实例;
- 主分片数在创建索引时指定,后续不能修改,除非Reindex;
- 用以解决数据的水平扩展问题。通过主分片,可以将数据分布到集群内的所有节点上
- 副本分片 - Replica Shared
- 用于解决数据高可用的问题,副本分片是主分片的拷贝;
- 副本分片数可以动态调整;
- 增加副本数,在一定程度上可以调高服务的读取吞吐量;
各节点中索引的分片分布情况:
以一个三节点的索引为例:
"blogs": { -
"settings": { -
"index": { -
"number_of_shards": "3",
"number_of_replicas": "1",
}
}
}
在索引blogs中创建了3个主分片,1个副本分片,看下cerebro中的展示:
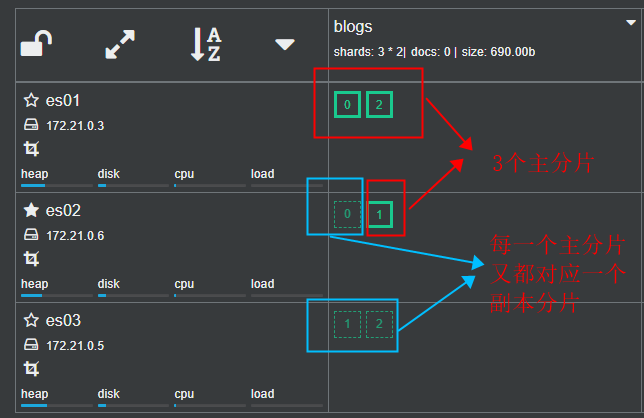
假设有一个节点es01出现故障导致导致其上的 主分片 0 和 主分片 2 丢失,可以通过es02 上的副本分片0 和es03 上的副本分片2 恢复主分片数据,从而保证数据完整性。
分片的设定
生成环境中分片设定,需要提前做好容量规划:
- 分片数设置过小
- 导致后续无法增加节点实现水平扩展;
- 单个分片上的数据量会过大,导致数据重新分配耗时;
- 分片数设置过大
- 影响搜索结果的相关性打分,影响统计结果的准确性;
- 单个节点上过多的分片,会导致资源浪费,同时也会影响性能;
查看集群的健康状况:
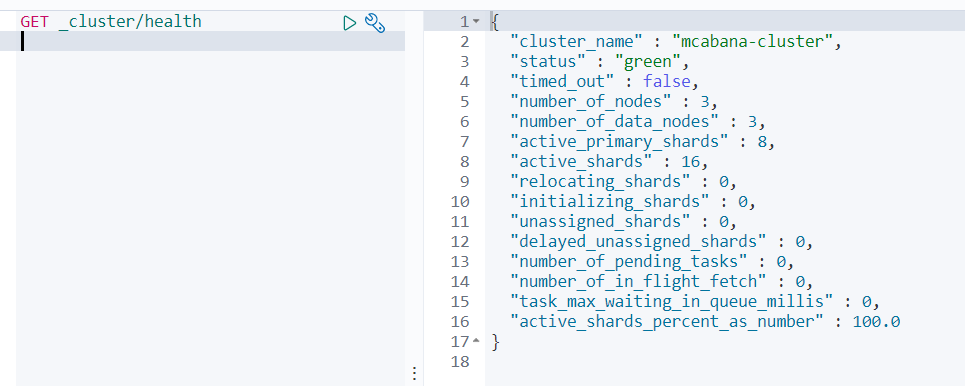
ElasticSearch 有三种颜色表示集群的健康状况:
- Green 主分片和副本分配正常分配
- Yellow 主分片正常分配,有副本分片未能正常分配
- Red 有主分片未能正常分片
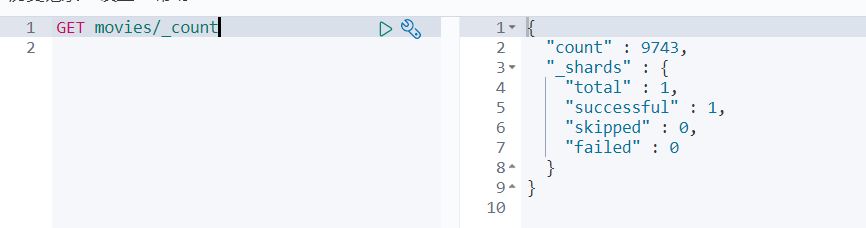
查看索引和分片

文档的CRUD与基本操作
文档读取:获取文档内容
Read:
// 获取movies索引中id为1的文档内容 GET movies/_doc/1

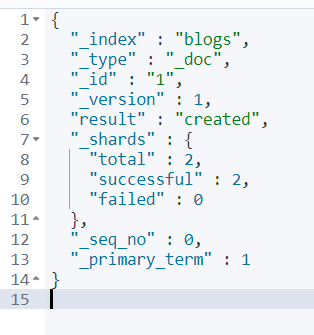
文档创建:
Index:如果文档不存在,则创建。如果存在,先删除现有文档,在创建新文档,版本加1
PUT blogs/_doc/1
{
"user": "Mike",
"comment": "you know"
}
创建成功:
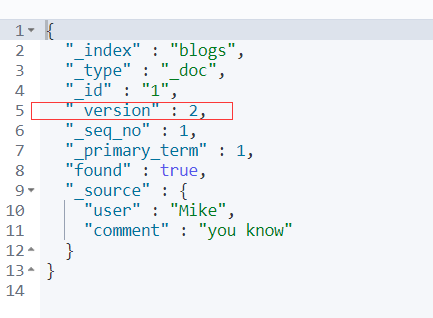
查看这个创建的文档:
GET blogs/_doc/1
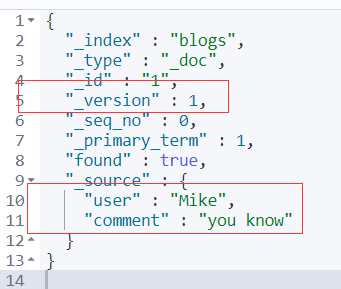
当前的version是1,如果在创建一次的话,按照Index的特性,删除这个添加新的,然后版本加1,继续创建测试:
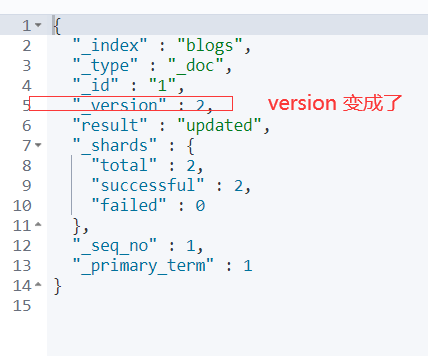
用get方法查看,还是2
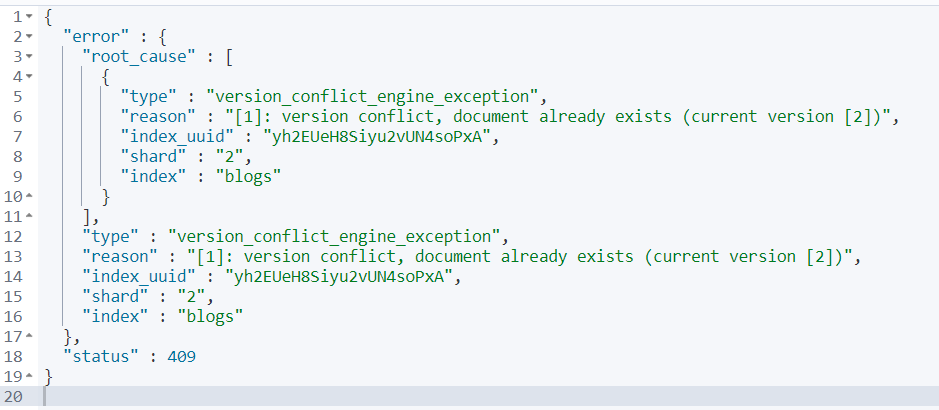
Create:创建文档,如果文档已存在,则失败;
PUT blogs/_create/1
{
"user": "Mike",
"comment": "you know"
}
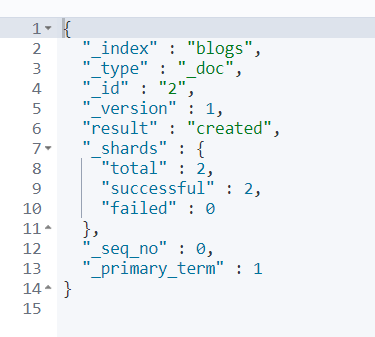
PUT blogs/_create/2
{
"user": "Mike",
"comment": "you know"
}
文档更新:
Update:文档必须存在,更新只会对相应字段做增量修改, 修改一次 version 加 1
更新时需要传递一个“doc”文件对象参数,否则会有 “x_content_parse_exception” 错误,例如:
PUT blogs/_doc/5/
{
"user": "Jerry",
"sex": "w"
}
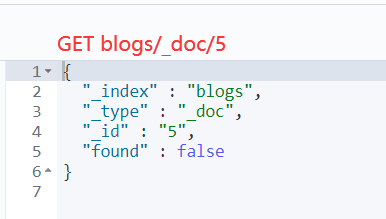
GET blogs/_doc/5
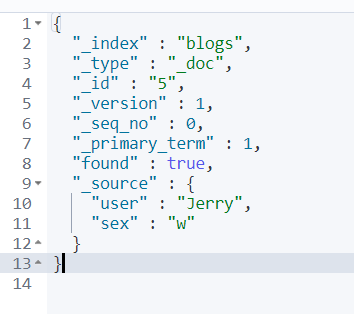
然后进行局部更新:
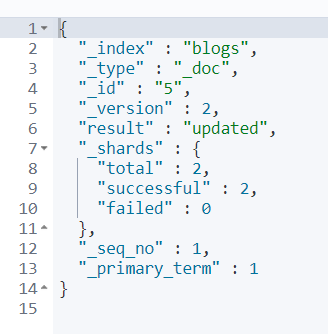
POST blogs/_update/5
{
"doc": {
"date": "198373",
"enable": "true"
}
}
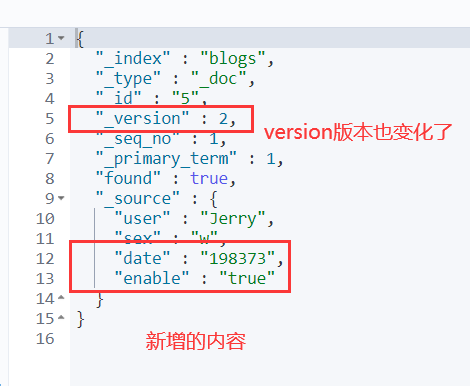
文档删除
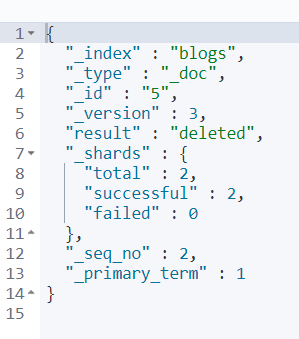
Delete:
DELETE blogs/_doc/5
Bulk API
发起REST API 是有网络开销的,且只能对一个索引进行操作,而Bulk API 支持一次请求中对多个索引进行多个操作。
支持的操作类型:
- Index
- Create
- Update
- Delete
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test2", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
对多个索引的多个操作,是一次发送的,每一条的执行结果都会返回。
Mget API 批量读取
前面的Bulk api 不支持读取功能,可通过mget api 实现一次读取多个文档
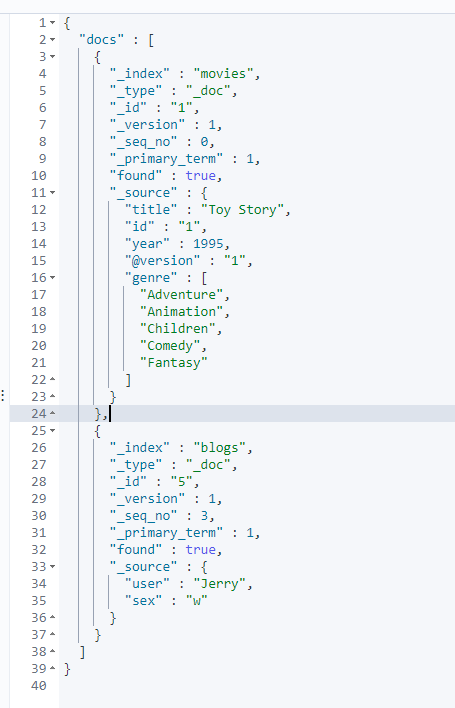
get _mget
{
"docs": [
{
"_index": "movies",
"_id": 1
},
{
"_index": "blogs",
"_id": 5
}
]
}
msearch 批量查询
POST kibana_sample_data_ecommerce/_msearch
{}
{"query" : {"match_all" : {}},"size":1}
{"index" : "kibana_sample_data_flights"}
{"query" : {"match_all" : {}},"size":2}
https://www.hugbg.com/archives/1834.html


2020-04-20 12:23 下午 1F
即使你忘记我,我也不会遗忘你! —从零开始的异世界生活