01 集群分布式模型及选主与脑裂问题
- Es分布式特性优点
- 存储的水平扩容,支持PB级数据
- 提高系统可用性,部分节点停止服务,集群服务不受影响
- Es的分布式架构
- 每个集群都有一个集群名字,各个节点通过指定集群名字,加入集群;
- cluster.name 设置
01-1 关于ElasticSearch 集群的集群信息,节点类型
关于集群信息,节点类型,以及多节点最佳实践等内容,在前面 《02 | ElasticSearch 基本概念》中有详细说明 -“基本概念二:节点,集群,分片及副本“
01-2 Master Eligible Nodes 选主流程
- 集群中每个节点启动时,默认就是Master Eligible 节点(可以理解为一种“获得竞选主资格的节点”);
- 只有Master Eligible Node 有选主资格,节点可通过配置node.master: false 放弃参加选主;
- 当集群第一个Master Eligible 节点启动时,他会把自己选为 Master 节点;
- 如果前面的 Master 失联,剩余的Master Eligible Node 会互相ping对方开始选主,node id 最小的为主节点Master;
01-3 ElasticSearch 集群的集群状态
关于集群状态,Es中一个集群状态信息(Cluster State)保存集群状态信息
- Cluster State 维护了一个集群中,必要的信息
- 包含所有节点信息
- 所有索引和其相关的Mapping 和 Setting 信息
- 分片的路由信息
- 在每个节点上都保存了一份相同的集群状态信息
- 只有Master 才可以修改集群状态信息,并负责同步给其他节点
- 如果任意节点都可以修改Cluster State ,会导致集群状态信息的不一致
01-4 脑裂问题
脑裂问题出现在“一个节点与其他节点无法通行情况下”,比如一个三节点集群:
- node1,node2,node3组成一个集群,其中node1 是master,因为网络原因无法与node2 node3通信
- node1 依然认为自己还是一个集群,并作为并主节点更新集群信息
- 而node2 和node3 会组成一个集群,并进行主节点选举,选出一个主节点
- 这样集群就同时存在了 两个主节点维护不同的Cluster State
- 当网络恢复时,其他几点就无法选择正确的主节点恢复“集群信息”
01-5 如何避免脑裂问题
7.0 版本之前
- 限定一个选举条件,设置quorum(仲裁),只要在Master Eligible 节点数大于 quorum时,才能进行选举、
- discovery.zen.minimum_master_nodes 设置为(Master Eligible / 2 + 1)
- 如果节点数小于这个值,则不选举
# 也可通过api 设置
PUT /_cluster/settings
{
"persistent" : {
"discovery.zen.minimum_master_nodes" : 2
}
}
7.0 以后
- 7.0 以后无需配置了,ElasticSearch 自己选择可以形成仲裁的节点
02 配置节点类型
一个节点默认是 Master Eligible,Date Node 和 Ingest Node
| 节点类型 | 配置参数 | 默认值 |
| Master Eligible | node.master | true |
| data node | node.data | true |
| ingest | node.ingest | true |
| coordinating only | 无 | 设置上面三个参数全部为false |
| maching learning | node.ml | true(需要 enable x-pack) |
03 分片与集群的故障转移
03-1 分片类型
分片是ElasticSearch分布式存储的基石
- 主分片
- Primary Shard 将一份索引数据,分散在多个data node上,实现存储的水平扩展
- 主分片数在索引创建时指定,如需更改需要重建索引
- 副本分片 Replica Shard
- 主分片的副本,主分片丢失,副本分片可以Promote 成主分片
- 副本分片可以动态调整,每个节点上都有完备的数据
- 通过增加副本分片的数量,一定程度提高读取吞吐量
03-2 分片数的设定
- 主分片数过小:
- 如果索引数据增长很快,集群无法通过增加节点实现对这个索引的数据扩展
- 单个分片的数据量就会很大,会产生热点数据问题
- 主分片数过大:
- 单个shard的容量很小,一个节点上有过多分片,影响新能
- 副本分片设置过多,会降低集群整体的写入性能
创建索引,指定分片

04 集群的故障转移
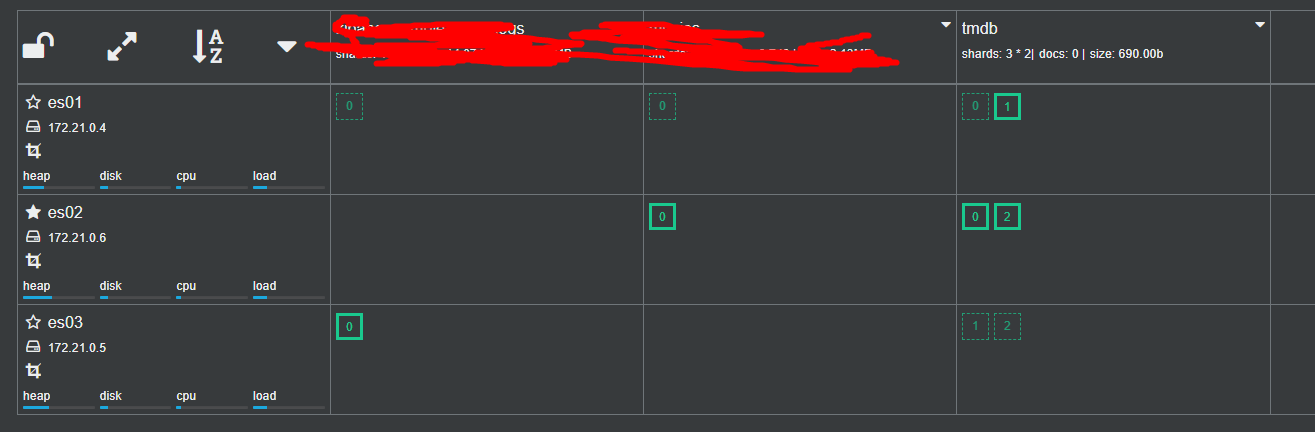
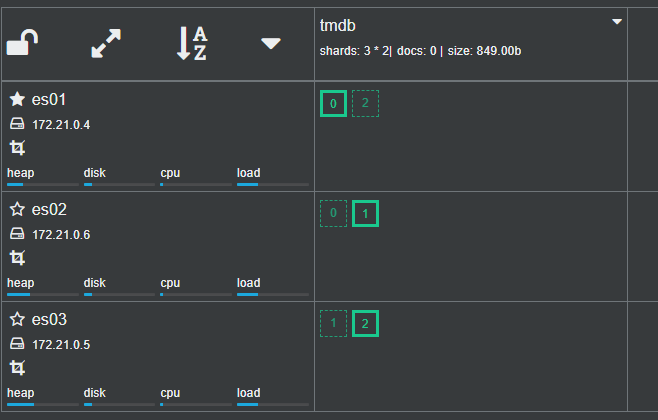
以当前的三节点集群为例:
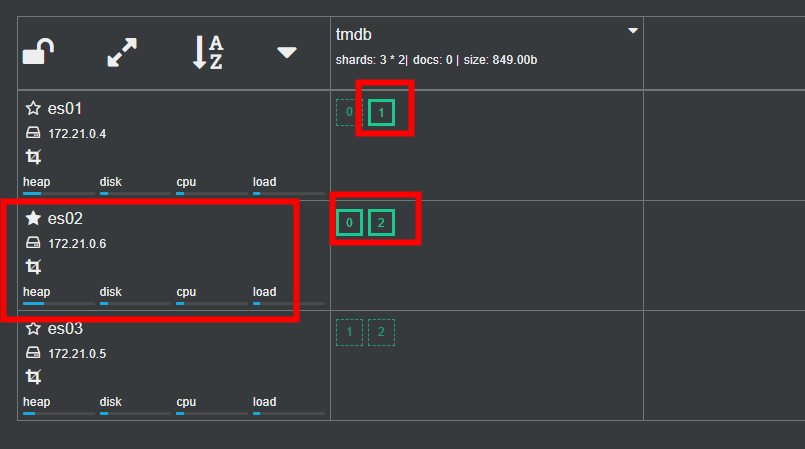
可以看到当前的 tmdb索引,在集群中有三个主分片其中 P1 在es01上,P0和P2在es02上,其中es02 是主节点
关掉es02,模拟主节点宕机,观察集群情况:
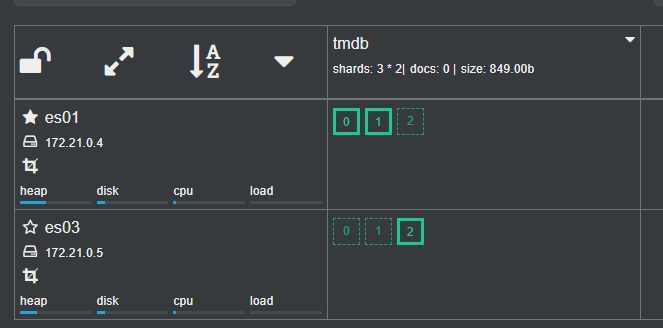
es02 节点已经没有了,tmdb索引依然是三个主分片,一个副本分片。与之前不同的是es01 选举为了新的Master,原es01上的副本分片0 提升为了P0,es03 上的副本分片2提升为了P2,从而保证了数据的完整。然后重新分配了副本分片。
由此可见,es集群的故障转移主要完成了一下内容:
- 重新选主
- 副本分片提升为主分片
- 副本分片重新分片
如果此时es02 恢复上线呢?

此时ES集群又对分片做了重新分配,维持分片个数不变的情况下,调整了分片分布位置。
并且es02 依然是主
curl -XGET 127.0.0.1:9200/_cluster/health

05 文档的分布式存储
ElasticSearch 通过分片存储数据,文档作为es的最小单位,存储在分片上,为了防止热点数据导致部分机器负载高,一些负载低,所以要把文档均匀的分布在不同的shard上。
如何保证文档可以均匀的分布在shard上?在时候就需要文档到分片的路由算法来确定。
05-1 文档到分片的路由算法
ElasticSearch 通过对文档ID结合节点主分片数量,进行取模运算就可得出文档所在节点。
- shard=hash(_routing) % number_of_primary_shards
- 通过hash算法可以确保文档均匀的分散到分片中
- 默认的_routing 是文档id
- 可以指定_routing,这样可以将一些文档分到指定的shard
- 这也是为什么创建索引后,主分片数不能随意更改的根本原因
05-2 文档更新流程
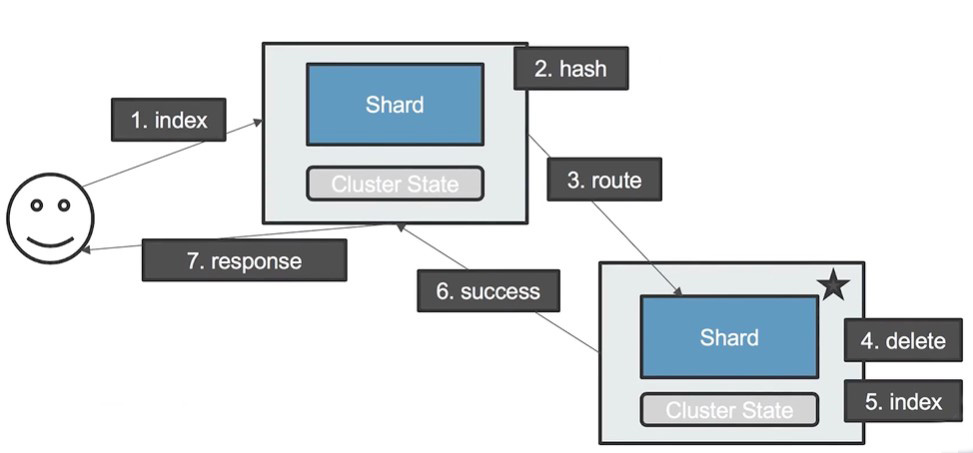
- 用户发起文档更新请求到Coordinating Node;
- Coordinating Node 通过哈希算法得出文档所在的各个Shard
- Coordinating Node 路由请求到对应的各个Shard上
- Shard收到请求,删掉原先的文档
- Shard创建新的文档
- Shard 将修改成功消息发给,路由来的 Coordinating Node
- Coordinating Node 将response发送给client
05-3 文档删除流程
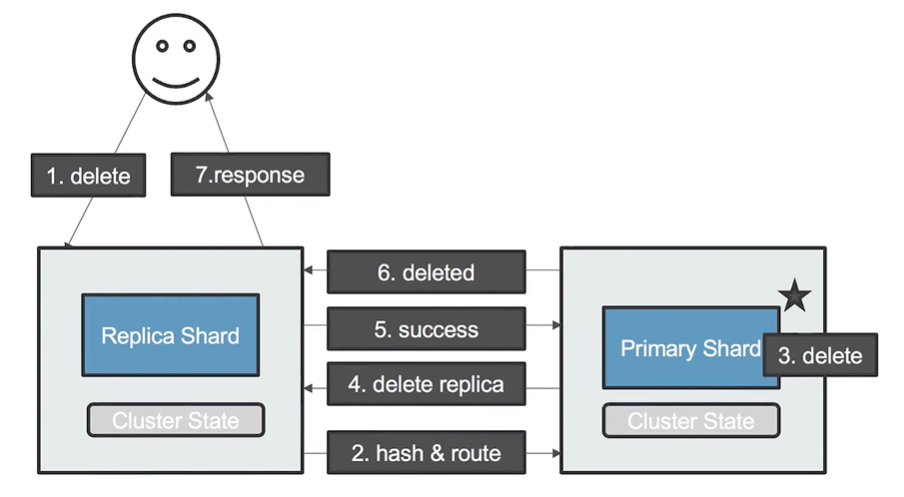
- 用户发起一个删除文档请求到Coordinating Node
- Coordinating Node 收到请求,通过哈希计算得到Primary Shard,并路由到所在分片
- Primary Shard 进行删除索引
- Primary Shard 通过查询Cluster State 找到 副本分片所在节点,然后发送 删除信息
- Replica Shard 删除文档,删除成功后,发送成功消息到 Primary Shard
- Primary Shard 将删除消息发的 Coordinating Node 上
- Coordinating Node 再发送Response 给 Client
https://www.hugbg.com/archives/2015.html


2020-04-03 1:18 下午 1F
风花之潇洒,雪月之空清,唯静者为之主;水木之荣枯,竹石之消长,独闲者操其权。 —菜根谭