01 Hot & Warm 架构概述
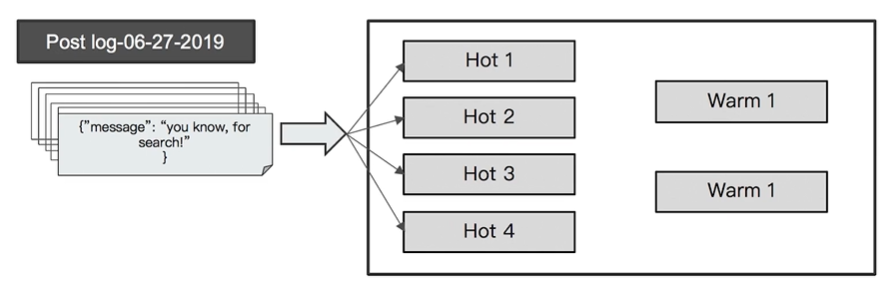
前面我们说到,应该设置单一节点单一角色的集群来充分利用硬件资源。其中Data Node 节点比价占用CPU RAM 还可以配备SSD。
其实也并非所有的Data Node 都需要较高配置,我们对存储的数据也可以进行分类,读写频繁的放到高配节点上,读写频率低的放到低配的节点上,以降低部署成本。
这种数据节点可以分为两类:
- Hot 节点(通常使用SSD): 索引不断有新文档写入。
- Warm 节点(通常使用HHD): 索引不存在新数据的写入,同时不存在大量的数据查询
01-1 Hot Nodes
- 用于数据的写入
- Indexing 对 CPU 和IO都有较高的要求,需要使用高配置的机器
- 存储的性能要好,可使用SSD
01-2Warm Nodes
- 用于保存只读的索引,比较旧的数据
- 通常使用大容量的HDD磁盘
02 配置 Hot & Warm Architecture
Hot Warm 架构的配置可以分为三步:
- 标记节点(hot或者warm)
- 配置热地数据到Hot Node
- 配置不常用数据到Warm Node
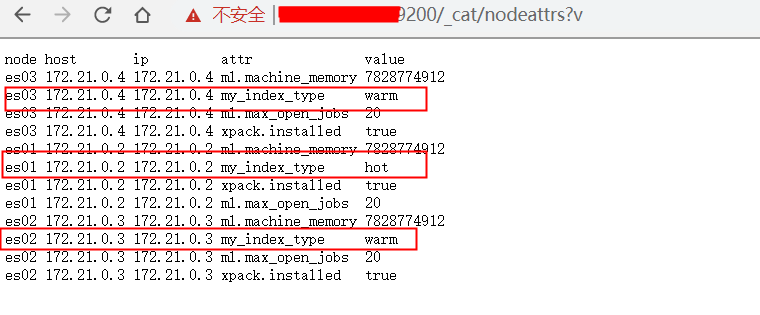
02-1 标记节点
节点标记可通过node.attr 指定
- 节点的 attribute 可以是任何的 key/value
- 可以通过ElasticSearch.yml 或则通过-E 命令指定 node.attr.my_index_type=hot
- 为es01 配置为hot
- elasticsearch.yml
- node.attr.my_index_type: "hot"
- 为es02 es03 配置warm
- elasticsearch.yml
- node.attr.my_index_type: "warm"
- 为es01 配置为hot
02-2 配置Hot 数据
- 创建索引时,指定将其创建在hot节点上
PUT logs-2020-04-10
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0,
"index.routing.allocation.require.my_index_type": "hot"
}
}
"index.routing.allocation.require.my_index_type": "hot" 指定分片
注意:

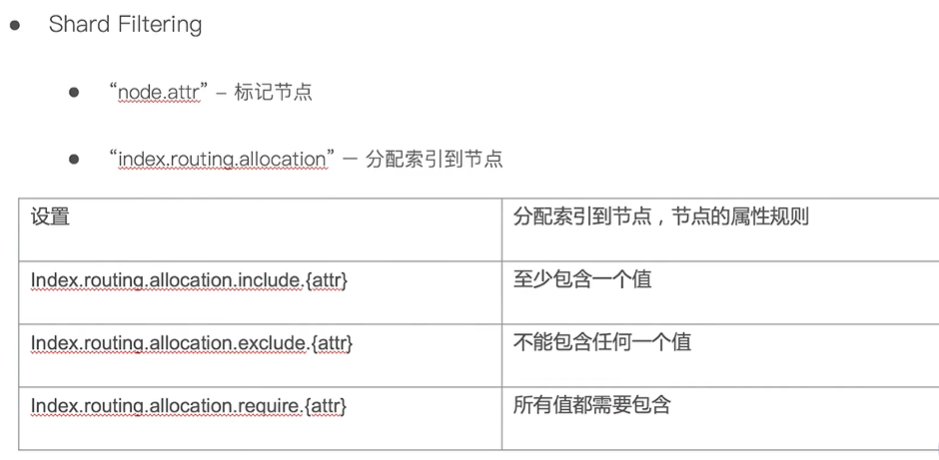
如上图,require 表示必须分配到某个节点,此外还有exclude 表示不允许分配到某个几点,include 表示可以分配到某个节点
然后写入一条数据
PUT logs-2020-04-10/_doc/1
{
"key": "test"
}
查看分片
GET _cat/shards?v
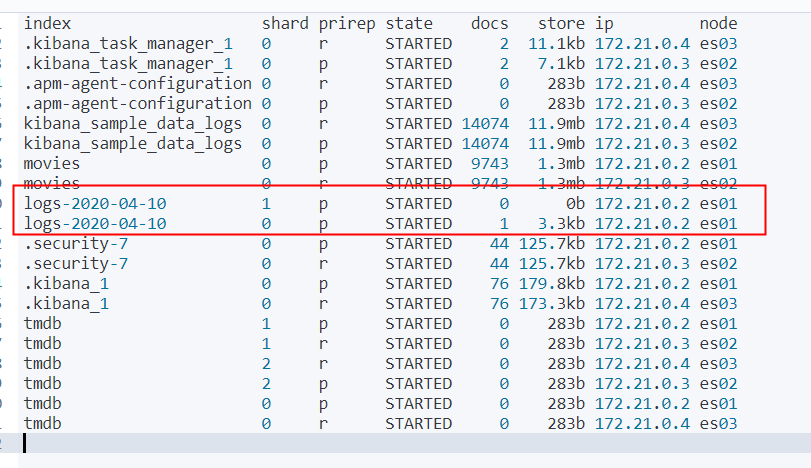
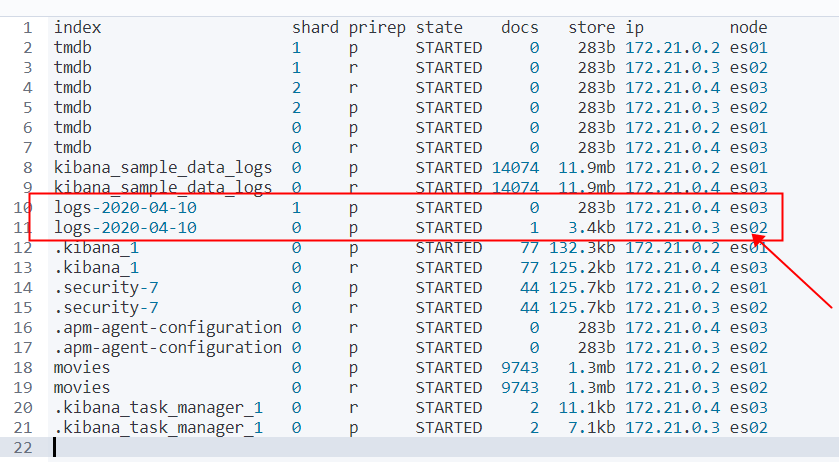
这个索引有两个主分片,都在es01 这个hot节点上
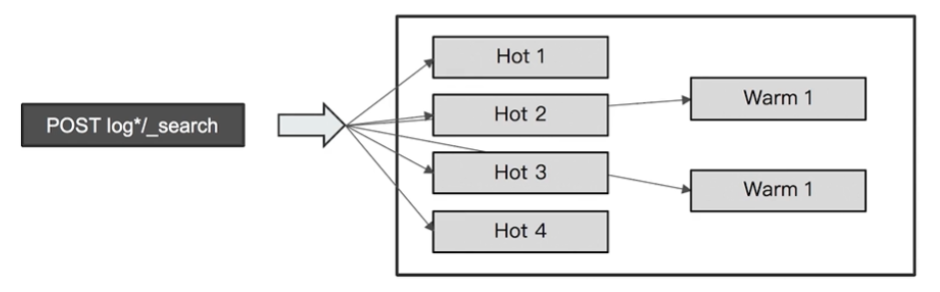
02-3 旧数据迁移到Warm 节点
- index.routing.allocation 是一个索引级的 dynamic setting, 可以通过API 在后期进行设定
- Curator / Index Life Cycle Management Tool

然后查看分片位置 get _cat/shards?v
索引两个分片已经切换到了 es02 和 es03 上了
03 Rack Awareness
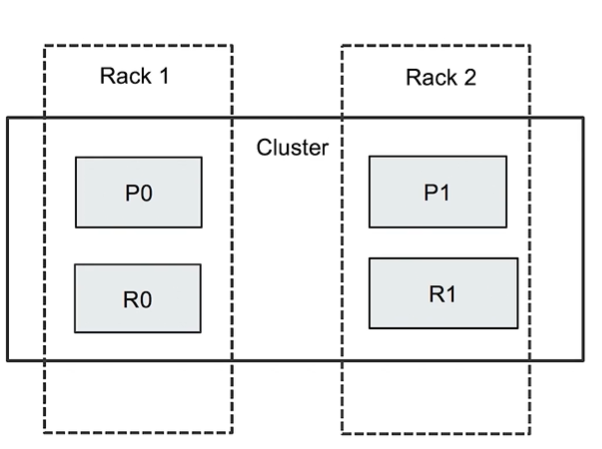
Rack Awareness 的作用是将索引的 主分片 和 副本分片 分布在不同“机柜”的不同节点上,是为了防止一个机柜断电,而导致整个索引不可用的情况出现。
如下图:索引分片时,如果不做干预,可能会导致索引 0 的主分片 P0 和副本分片R0 同时分布在Rack1 上,如果Rack 1 断电,则会导致整个 索引 0 不可用。
配置 Rack Awareness
Rack Awareness 的实现机制
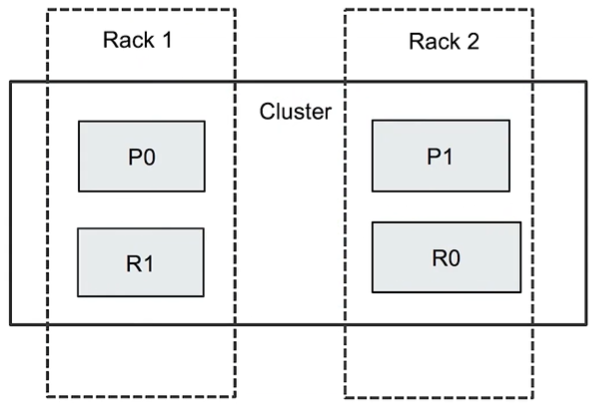
ElasticSearch 通过对节点进行标记,同一个机柜的节点,标记相同的rack id,然后开启 Rack Awareness ,之后创建索引,其分片就会分布在不同的Rack id 的节点上。
如图:
索引0 的 P0 分片和 R0 分片分布在不同的Rack 上,这样不管是Rack 1 断电还是Rack 2 断电,都可以保证 索引0 可用。
注意:
如果设置了 Rack Awareness ,而标记的Rack Id 却只有一个,则会导致集群健康状态成 “黄色”表示有分片无法分配。
# 可通过 GET _cluster/health GET _cluster/allocation/explain?pretty 查看错误原因
配置过程:
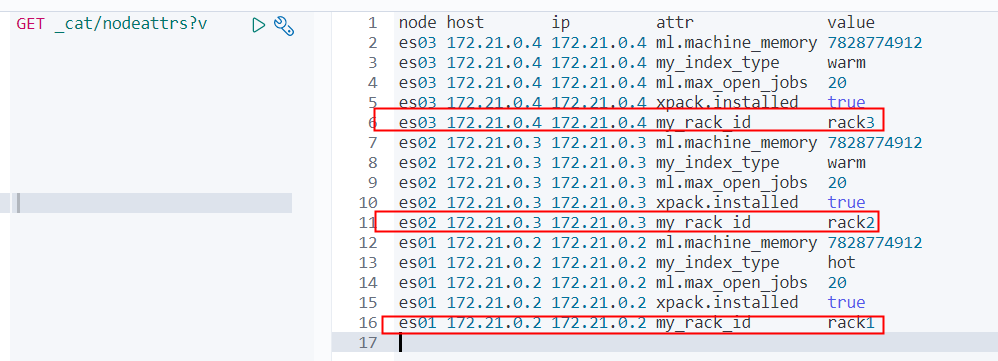
# Rack Awareness 配置过程 1. 标记Rack id echo 'node.attr.my_rack_id: "rack1"' >>/data/ELKStack/es01/conf/elasticsearch.yml echo 'node.attr.my_rack_id: "rack2"' >>/data/ELKStack/es02/conf/elasticsearch.yml echo 'node.attr.my_rack_id: "rack3"' >>/data/ELKStack/es03/conf/elasticsearch.yml 2. 重启各节点 -- $ elk -q es -s restart /usr/lib/python2.7/site-packages/requests/__init__.py:91: RequestsDependencyWarning: urllib3 (1.25.3) or chardet (2.2.1) doesn't match a supported version! RequestsDependencyWarning) Restarting es01 ... done /usr/lib/python2.7/site-packages/requests/__init__.py:91: RequestsDependencyWarning: urllib3 (1.25.3) or chardet (2.2.1) doesn't match a supported version! RequestsDependencyWarning) Restarting es02 ... done /usr/lib/python2.7/site-packages/requests/__init__.py:91: RequestsDependencyWarning: urllib3 (1.25.3) or chardet (2.2.1) doesn't match a supported version! RequestsDependencyWarning) Restarting es03 ... done 3. 检查es 的标记
4. 开启Rack Awareness
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.awareness.attributes": "my_rack_id"
}
}
5. 创建测试索引
PUT awareness_test
{
"settings":{
"number_of_shards":2,
"number_of_replicas":1
}
}
PUT awareness_test/_doc/1
{
"key": "test"
}
6. 查看shard分布
GET _cat/shards?v
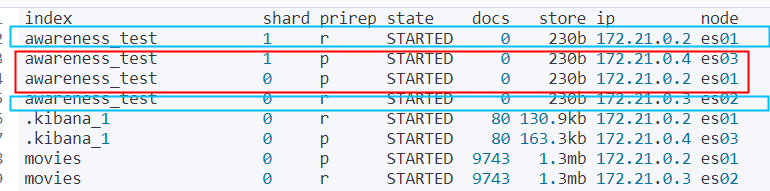
主分片和副本分片,已经分布在不同的 rack上了。
另外还可以强制设置 rack
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.awareness.attributes": "my_rack_id",
"cluster.routing.allocation.awareness.force.my_rack_id.values": "rack1,rack2"
}
}
# 强制分配在 rack1 和 rack2上
https://www.hugbg.com/archives/2225.html


2020-04-18 11:42 上午 1F
还君明珠双泪垂,恨不相逢未嫁时。 —节妇吟·寄东平李司空师道
2020-04-18 11:56 上午 2F
有伤害人的人存在的话,也会有能抚慰伤痕的人 —水果篮子