在旧版的ElasticSearch 中创建索引默认设置5个主分片,7.0 开始默认只有一个主分片。
单个分片的优点在于,查询算分聚合不准确的问题都可以避免,而其影响在于单个索引,单个分片,无法实现集群的水平扩展,即使增加新的节点,也无法实现水平扩展。
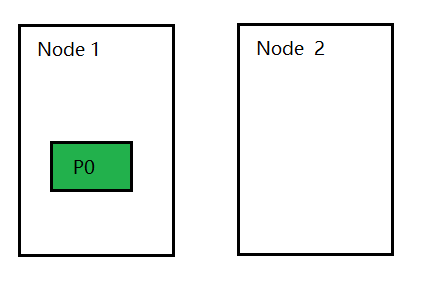
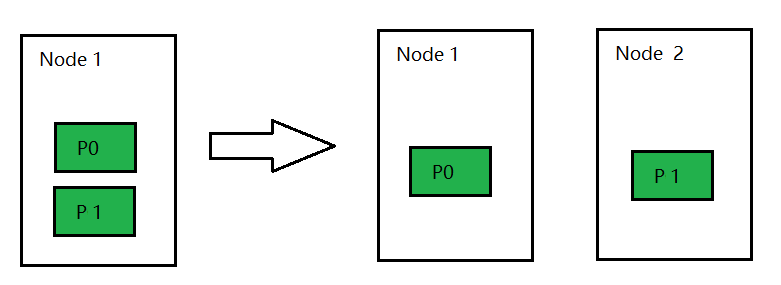
集群增加节点后,ElasticSearch 会自动进行分片的移动,也叫Shard Rebalancing
关于分片数
- 当分片数 > 节点数时
- 一旦集群中有新的数据节点加入,分片就可以自动进行分配
- 分片在重新分配时,系统不会有 downtime
- 多分片的优势:
- 查询可以并行执行
- 数据可以分散到多个机器
- 分片过多引起的问题
- 每个分片是一个Lucene 的索引,会占用机器资源
- 分片过多会增加性能开销
- 每次搜索的请求,需要从每个分片上获取数据
- 分片的mata 信息有Master节点维护,过多的分片,会增加管理的负担,控制在10W以内
如何确定主分片数
- 从数据量角度
- 日志类应用,单个分片不要大于 50GB
- 搜索类应用,单个分片不要大于 20GB
- 单个分片存储大小的影响
- 提高Update性能
- Merge时,减少所需的资源
- 丢失节点后,具备更快的恢复速度 / 便于分片在集群内Rebalancing
如何确定副本分片数
- 副本分片是主分片的拷贝
- 可以提高系统可用性,提高查询速度,防止数据丢失
- 需要占用和主分片一样的资源
- 对性能的影响
- 副本会降低数据的索引速度,有几份副本就会有几倍的CPU资源消耗在索引上
- 会减缓对主分片的查询压力,但是会消耗同样的内存资源
- 如果硬件资源充足,提高副本数,可以提高整体的查询QPS
调整分片总数,避免分配不均衡
ElasticSearch的分片策略会尽量保证节点上的分片数大致相同
扩容的新节点没有数据,导致新索引集中在新的节点
热点数据过于集中,可能会产生新的性能问题
ElasticSearch 分片平衡参数
cluster.routing.rebalance.enable
这个参数用来控制是否对分片进行平衡,以及对哪些类型的分片进行平衡。
参数值:
- all 对所有分片进行平衡
- primaries 只能对主分片进行平衡
- replicas 只对副本分片进行平衡
- none 禁用平衡功能
index.routing.allocation.total_shards_per_node
控制单个索引在一个节点上的最大分片数,默认不限制。
创建索引时,这个值可以设置的小一些,以便索引的分片更平均的分布到集群的所有节点上。
cluster.routing.allocation.total_shards_per_node
控制全局范围内,分配给单个节点的最大分片数。
https://www.elastic.co/guide/en/elasticsearch/reference/current/allocation-total-shards.html
集群容量规划
一个集群共需要多少个节点,一个索引要设置几个分片?在规划上需要保存一定的余量,当负载出现波动,节点出现丢失时,还能正常运行。
做容量规划时,一些需要考虑的因素
- 机器的软硬件配置
- 单挑文档的尺寸 / 文档的总数据量 / 索引的总数据量(Time base 数据保留的时间)/ 副本分片数
- 文档是如何写入的(Bulk 的尺寸)
- 文档的复杂度,文档是如何进行数据读取的(怎么样的查询和聚合)
评估业务的性能需求
- 数据吞吐量及性能需求
- 数据写入的吞吐量,每秒要求写入多少数据?
- 查询的吞吐量?
- 单条查询可接受的最大返回时间?
- 关于数据
- 数据的格式和数据的Mapping
- 实际的查询和聚合长的什么样的
常见的模式
- 搜索类:
- 搜索类一般使用固定大小的数据集
- 搜索的数据集增长相对比较缓慢
- 日志类:
- 基于时间序列的数据
- 数据每天写入,增长速度较快
- 结合Warm Node 做数据的老化处理
硬件配置:
- Hot 数据节点,尽可能使用SSD
- 搜索等性能要求高的场景,建议SSD
- 按照1:10 的比例配置内存和硬盘
- 日志和查询并发低的场景,可以考虑使用机械硬盘存储
- 按照1:50 的比例配置内存和硬盘
- 单节点数据建议控制住 2TB 以内,最大不建议超过 5TB
- JVM配置机器内存的一半,JVM内存配置不建议超过32G
容量规格案例1:固定大小的数据集
比如商品信息库
- 一些特性
- 被搜索的数据集很大,但是增长相对比较慢(不会有大量的写入)
- 更关心搜索和聚合的读取性能
- 数据的重要性与时间范围无关,关注的是搜索的相关度
- 估算索引的数据量,然后确定分片大小
- 单个分片的数据量不要超过20GB
- 可以通过增加副本分片,提高查询的吞吐量
拆分索引
- 如果业务上有大量的查询是基于一个字段进行Filter,该字段又是一个数量有限的枚举值
- 例如订单所在的地区
- 如果在单个索引有大量的数据,可以考虑将索引拆分成多个索引
- 查询性能可以得到提高
- 如果要对多个索引进行查询可,还是可以在查询中指定多个索引得以实现
- 如果业务上有大量的查询是基于一个字段进行Filter ,该字段值并不固定
- 可以启用routing功能,按照Filter字段的值分布到集群中不同的shard,降低查询时相关的shard,提高CPU使用率
容量规划2: 基于时间序列的数据
- 相关的用案
- 日志/指标/安全相关的Events
- 舆情分析
- 一些特性
- 每条数据都有时间戳,文档基本不会被更新(日志和指标数据)
- 用户更多的会查询近期的数据,对旧的数据查询相对较少
- 对数据写入的性能要求高
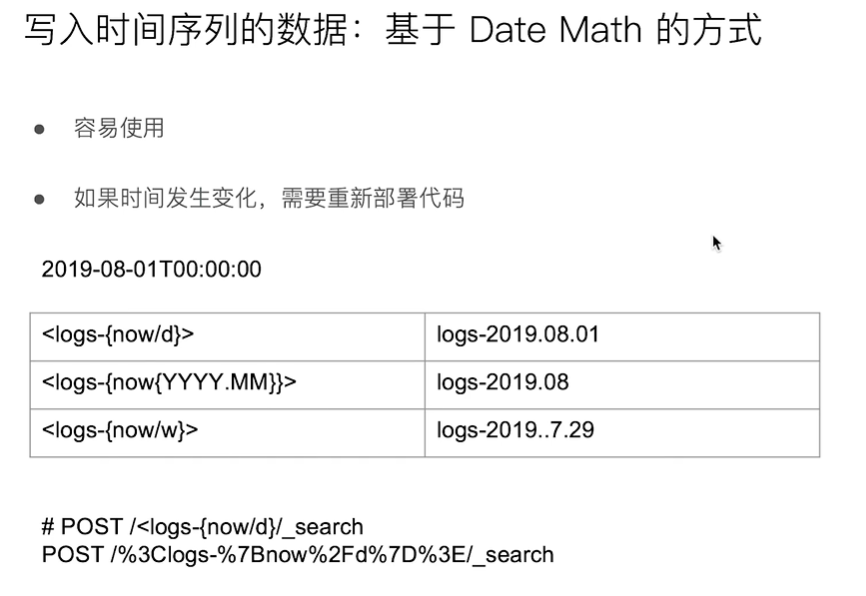
创建基于时间序列的索引
- 创建 time-based 索引
- 在索引的名字中增加时间信息
- 按照 每天 / 每周 / 每月 的方式进行划分
- 优势
- 更加合理的组织索引,便于对索引做老化处理
- 利用Hot Warm
- 删除的效率高
- 更加合理的组织索引,便于对索引做老化处理
https://www.hugbg.com/archives/2280.html


2020-04-18 12:55 下午 1F
如果说怪盗是一个技艺精湛,盗取财宝的艺术家,那么侦探就只是跟在怪盗后面吹毛求疵,充其量不过是个评论家。 —名侦探柯南
2020-04-18 8:40 下午 2F
饭可以一日不吃,水可以一日不喝,但题不可以一日不贺 —贺指导